マルチモーダルAIは、文章だけでなく、画像・音声・動画など複数の情報形式を扱えるAI。
画像を見ながら質問へ答えたり、音声で会話したりできます。
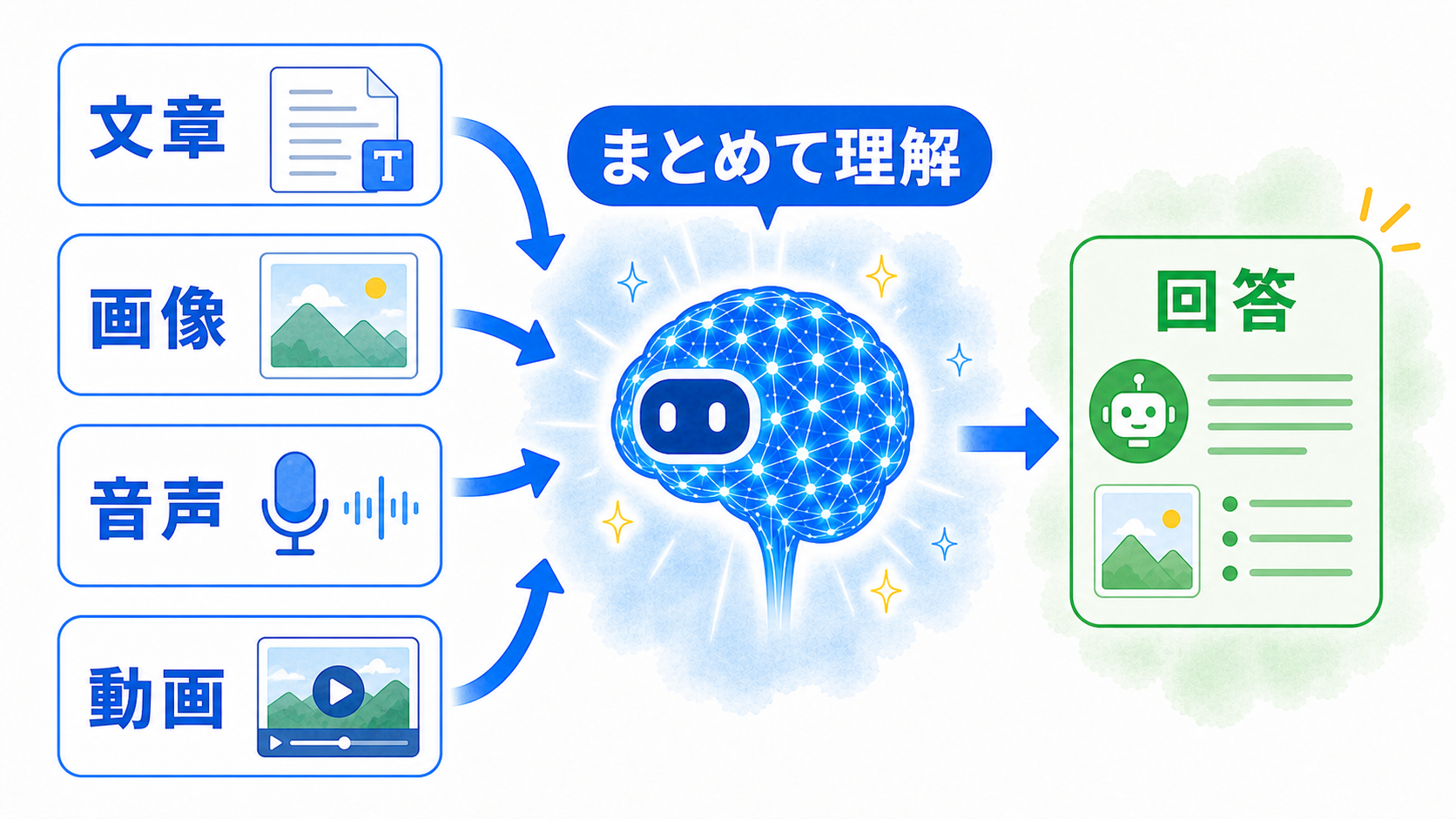
「モーダル」は、情報の種類を表す
マルチモーダルのモーダルは、文章、画像、音声など、情報を伝える形式を指します。ひとつの形式だけを扱うのではなく、複数の形式を組み合わせて理解・生成するAIがマルチモーダルAIです。
たとえば画面のスクリーンショットを渡して「このエラーの原因は?」と文章で質問する使い方では、画像と文章を一緒に扱っています。
質問、資料、コードなどの文字情報。
写真、図、画面、動きなどの視覚情報。
話した内容、音、声のやり取り。
複数の情報を組み合わせると、伝えやすくなる
文章だけでは説明しにくい内容も、画像や音声を一緒に渡すと共有しやすくなります。長い画面説明を書く代わりにスクリーンショットを見せたり、キーボードを使わず声で質問したりできます。
AI側も、画像内の文字や配置、音声で話された内容などを手がかりに回答します。利用できる形式や精度は、サービスやモデルによって異なります。
入力と出力の両方に、さまざまな組み合わせがある
画像を入力して文章で説明させるだけでなく、文章から画像を生成したり、音声へ音声で答えたりするAIもあります。「マルチモーダルAI」と呼ばれていても、すべての形式へ対応しているとは限りません。
何を入力でき、何を生成できるのかを確認すると、そのAIでできることが分かりやすくなります。
写真や画面を読み取り、内容を説明する。
指示された内容をもとに画像を生成する。
話した内容を理解し、声で返答する。
ChatGPT、Claude、GeminiもマルチモーダルAI
身近な生成AIサービスでは、すでにマルチモーダルAIが使われています。文章で質問するだけでなく、画像やファイルを渡したり、音声で会話したりできます。
ただし、利用できる入力・出力形式や機能は、サービス、モデル、利用プランなどによって異なります。
文章、画像、ファイル、音声などを使ってやり取りできる。
文章に加えて、画像や文書ファイルなどを読み取れる。
文章、画像、音声、動画など、複数形式の情報を扱える。
見えている・聞こえているから、正しいとは限らない
画像内の小さな文字を読み違えたり、似た物体を取り違えたり、音声を聞き間違えたりすることがあります。マルチモーダルでもハルシネーションは起こります。
また、写真、録音、画面共有には個人情報や機密情報が含まれやすいため、送信前の確認が必要です。重要な判断では元データとAIの説明を照合します。
小さな文字や複雑な画像を誤認する場合がある。
画像や音声へ映り込む情報を確認する。
重要な内容は元データと照合する。
ここまでのまとめ
マルチモーダルAIは、文章、画像、音声、動画など複数の情報形式を扱うAIです。伝え方と利用場面が広がる一方、読み取りミスや情報の取り扱いには注意が必要です。
マルチモーダルAIは、AIとのやり取りを「文字だけ」から広げる仕組みです。