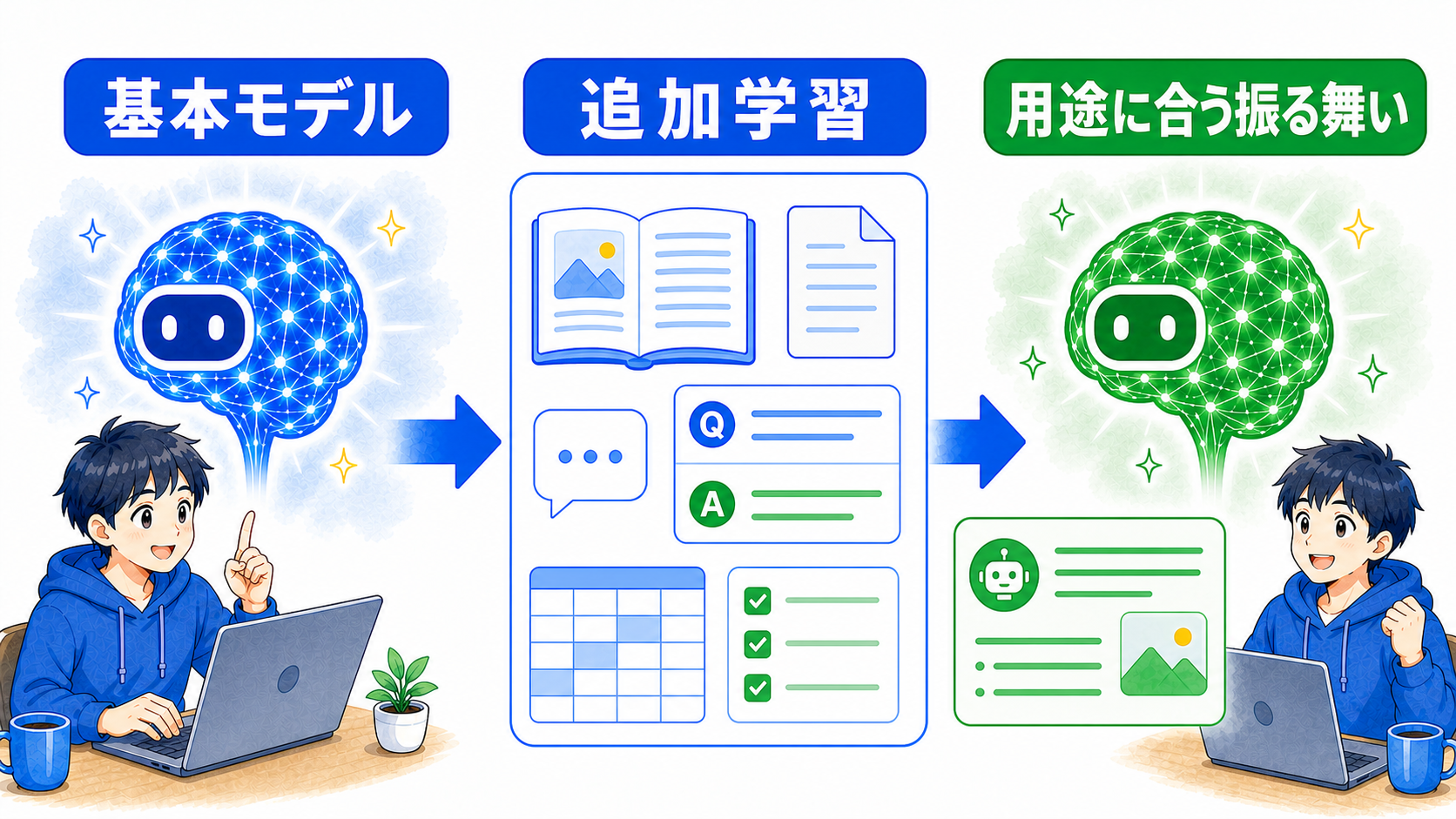
ファインチューニングは、学習済みのAIモデルへ追加の例を学ばせ、特定用途に合う振る舞いへ調整する方法。
新しいAIをゼロから作るのではなく、基本モデルを目的に合わせて仕上げます。
既存モデルを、目的に合う振る舞いへ調整する
LLMなどの基本モデルは幅広い質問へ答えられます。ファインチューニングでは、そのモデルへ追加の学習データを与え、特定の回答形式や文章の傾向を身につけさせます。
たとえば、問い合わせ文を決められたカテゴリーへ分類する例を多数学ばせると、同じ形式の分類を安定して行いやすくなります。単にプロンプトへ一度指示するのではなく、モデルの振る舞い自体を調整する方法です。
幅広い用途に対応できる学習済みモデル。
望ましい入力と出力の組み合わせを用意する。
目的に合う形式や傾向で回答しやすくなる。
対応サービスへ学習データを渡して行う
ファインチューニングは、AIとの会話画面で「この回答を覚えて」と頼む作業ではありません。一般的には、追加学習に対応したサービスや開発環境を使います。
入力と望ましい出力の例をアップロードし、対応モデルを追加学習する。
モデル、学習データ、学習方法を設定して調整する。
公開モデルを自分で調整する。自由度は高いが、専門知識も必要になる。
基本的な流れは、回答例を用意する → 対応サービスへアップロードする → 学習を実行する → 調整後モデルをAPIから利用する、となります。
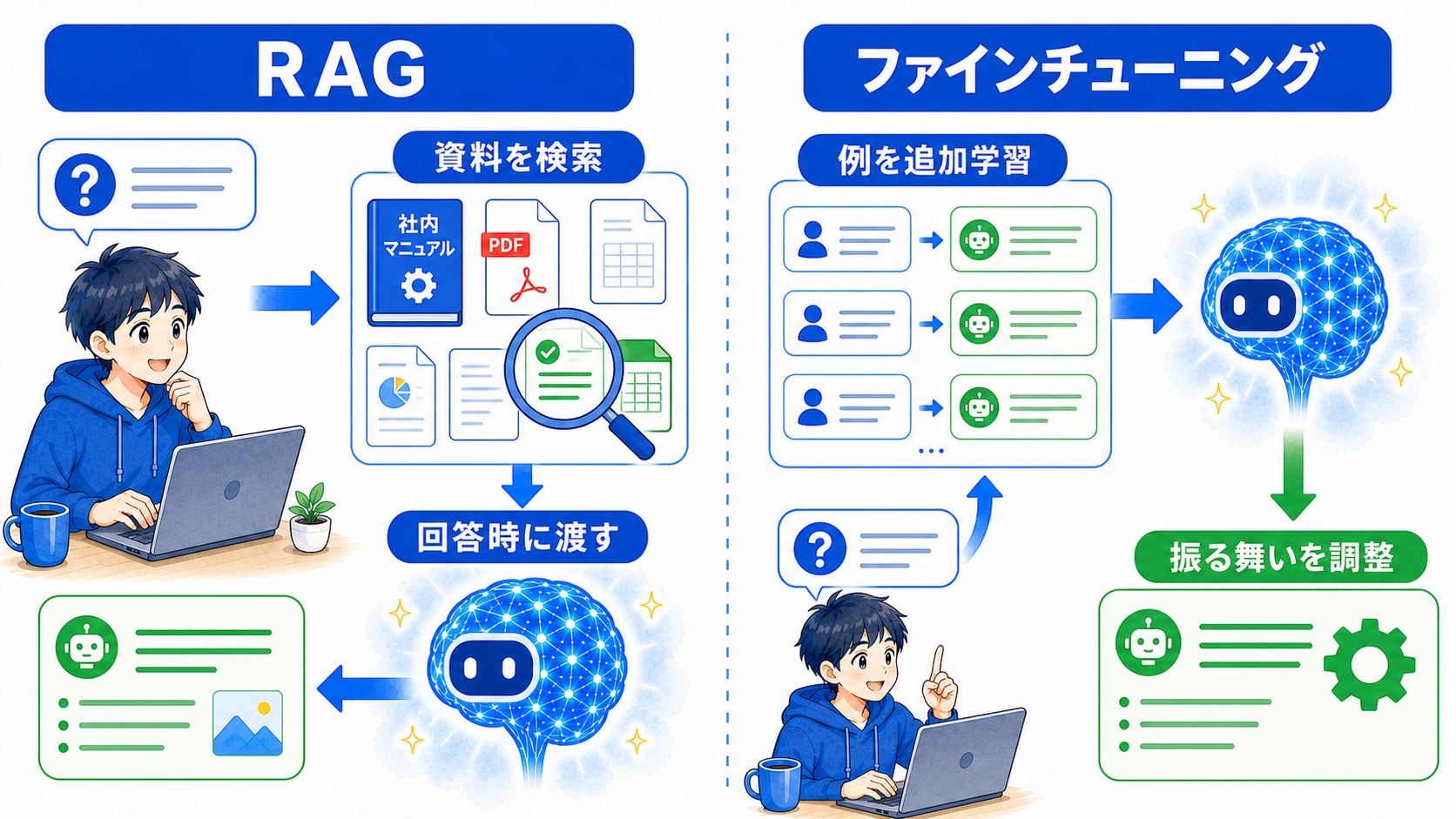
RAGは資料を渡す、ファインチューニングは振る舞いを学ばせる
RAGとファインチューニングは、どちらもAIを用途に合わせる方法ですが、役割が異なります。RAGは回答時に関連資料を探して渡し、ファインチューニングは事前の追加学習で答え方や判断傾向を調整します。
最新の商品情報や社内規程を答えさせたいなら、資料を更新しやすいRAGが向いています。決まった形式で分類・出力させたいなど、繰り返す振る舞いを整えたい場合はファインチューニングが候補になります。
何でも覚えさせるための方法ではない
ファインチューニングへ大量の資料を入れれば、その内容を正確に暗記していつでも答えられる、というものではありません。学習した情報をどのように保持・再現するかは保証されず、更新も簡単ではありません。
文章のトーン、出力形式、分類方法など、何度も使う振る舞いの調整に向いています。まずプロンプトやRAGで解決できないかを確認し、それでも安定しない場合に検討されることが多い方法です。
一定の形式、分類、文章傾向を繰り返したい。
頻繁に変わる事実を正確に覚えさせたい。
プロンプト改善やRAGで目的を満たせるか確認する。
学習データの品質が、振る舞いに影響する
追加学習に使う例が間違っていたり、偏っていたりすると、その傾向もモデルへ反映される可能性があります。望ましい回答例を用意するだけでなく、調整後モデルを別のデータで評価することが必要です。
個人情報や機密情報を学習データへ含めないこと、想定外の質問で危険な回答をしないか確認することも重要です。
目的に合う、正確で一貫した学習データを使う。
学習に使っていない入力でも期待どおりか試す。
機密情報や望ましくない回答傾向を見直す。
ここまでのまとめ
ファインチューニングは、学習済みモデルへ例を追加学習させ、特定用途に合う振る舞いへ調整する方法です。資料の内容を参照させるRAGとは役割が異なります。
ファインチューニングは、AIへ資料を持たせる方法ではなく、仕事のやり方を追加で練習させる方法です。