RAGは、AIが回答を作る前に、質問と関係する資料を検索して参考情報として読む仕組み。
AIがもともと知らない社内文書や独自資料についても、その内容をもとに答えやすくなります。
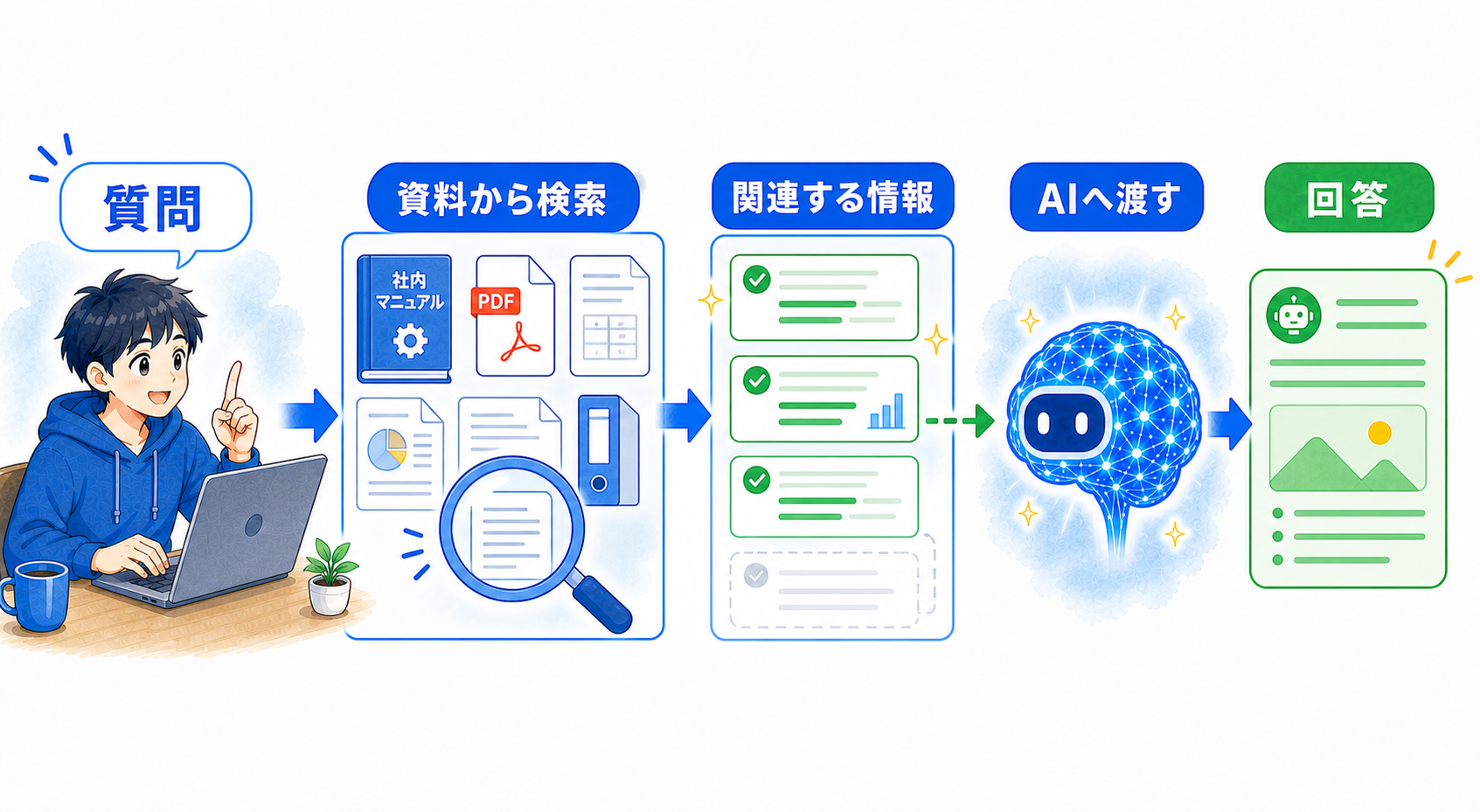
RAGは「検索してから答える」仕組み
RAGは、Retrieval-Augmented Generationの略で、日本語では検索拡張生成と呼ばれます。難しそうな名前ですが、やっていることは「関連資料を検索し、その内容をAIへ渡してから回答させる」です。
たとえば会社のAIへ「有給休暇は何日前までに申請する?」と質問したとします。一般的なAIは、その会社独自のルールを知りません。RAGがあれば、社内規程から該当箇所を探し、その内容を参考に回答できます。
これはAIモデル自体へ社内ルールを再学習させることとは異なります。質問のたびに必要な資料を探して、今回の回答に使うコンテキストへ追加するイメージです。
登録された資料から、質問に関係する部分を探す。
見つかった情報を、回答時の参考資料として加える。
質問と参考資料をあわせて、AIが回答を作る。
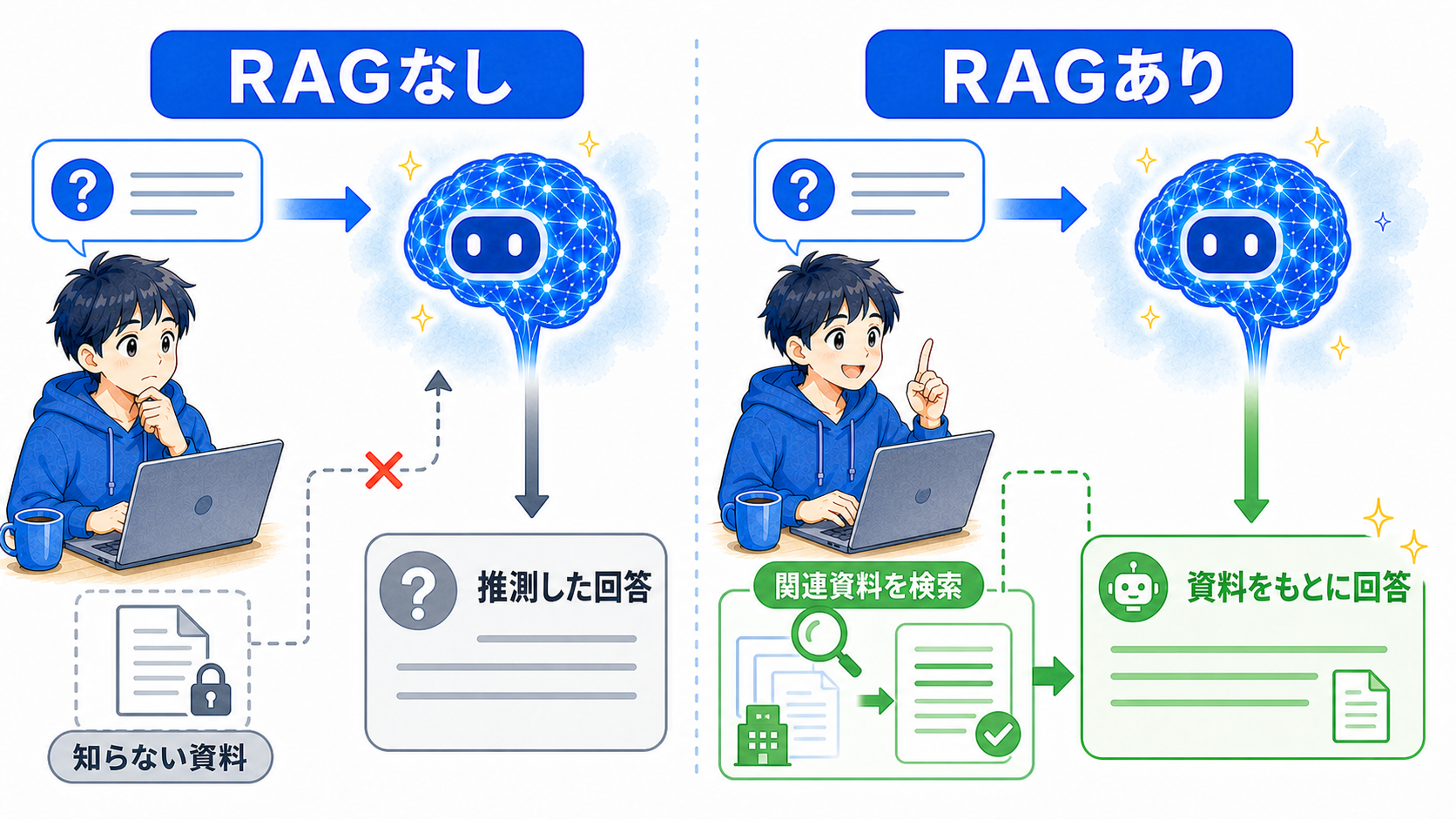
RAGがないと、AIは知らない資料について推測しやすい
LLMは、学習した情報や現在のコンテキストをもとに回答します。その中に会社独自の規程や、最近更新された商品情報がなければ、正確な内容は分かりません。
それでも自然な文章は作れるため、知らない内容を一般知識から推測して答えることがあります。RAGは、回答前に関連資料を渡すことで、独自情報や更新された情報を根拠にしやすくします。
大量の資料から、質問に合う情報を毎回探せる
チャットへ資料を直接添付して質問する方法も、AIへ参考情報を渡すという点では似ています。少数の資料をその場で読むなら、ファイル添付だけで十分なこともあります。
RAGが特に役立つのは、あらかじめ多くの資料を用意し、質問のたびに関係する部分だけを自動で探したい場合です。社内問い合わせ、製品マニュアル、過去の議事録などを対象にした質問回答でよく使われます。
検索では、単語が完全に一致する箇所だけでなく、質問と意味が近い文章を探す方法も使われます。そのため、資料と少し違う言い方で質問しても、関連箇所を見つけられる場合があります。
今回使う少数の資料を、自分で選んでその場で渡す。
用意された多くの資料から、関係する情報を毎回探す。
社内規程、問い合わせ履歴、商品資料などの検索。
RAGを使っても、必ず正しい回答になるわけではない
RAGはAIへ根拠となる資料を渡しやすくしますが、正しさを保証する仕組みではありません。検索で必要な箇所を見つけられなかったり、資料自体が古かったり間違っていたりすれば、回答もずれる可能性があります。
また、閲覧権限のない社内資料が検索結果へ混ざらないようにする管理も重要です。回答に参照元を表示し、人が元資料を確認できるようにすると、安心して使いやすくなります。
質問に本当に関係する資料が選ばれているかを見る。
古い情報や間違った情報をそのまま使わない。
根拠を確認でき、見てよい資料だけを検索対象にする。
ここまでのまとめ
RAGは、質問に関連する資料を検索し、その内容をAIへ渡してから回答を作る仕組みです。AIモデル自体を再学習させなくても、社内文書や独自資料を回答へ反映しやすくなります。
RAGは、AIにすべてを暗記させるのではなく、必要なときに資料を探して読ませる仕組みです。